|
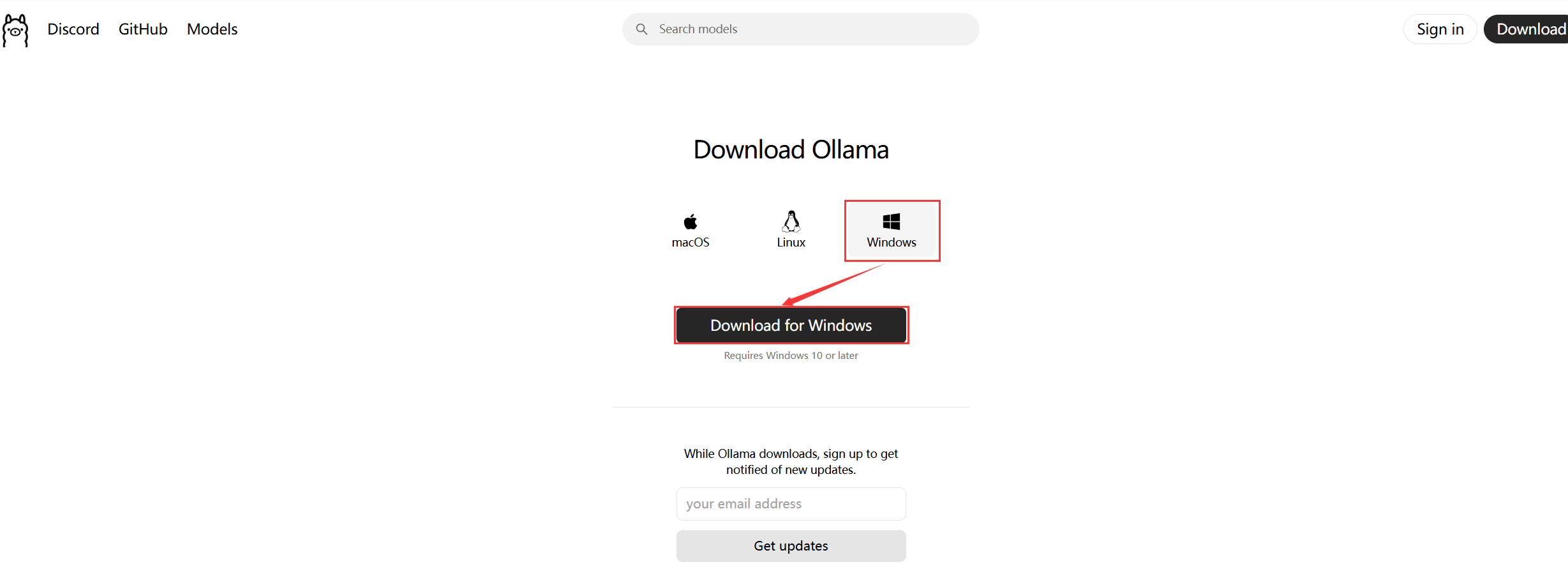
DeepSeek本地部署详细教程 前言 DeepSeek作为国内开源大模型,当前应该是最火的大模型之一,相比较于国外的大模型,可谓是我们的福音了,因为我们不用再FQ也能够使用,而且当前来说是免费的,不用收费。 为什么要部署到本地?那么,明明可以在官网直接使用网页版进行使用,为什么还要部署到本地呢,主要有以下几个优势。 隐私性高:数据都是在在本地运行,无需上传到云端,从而避免了数据泄露的风险。 稳点性强:不容易受到网络波动的影响,模型的运行更加稳定。 可定制性强:可以根据需求调整模型的参数,满足个性化的需求。 一、部署前的准备 1.1硬件要求 硬件要求 最低配置 推荐配置显卡 NVIDIA GTX 1060 (6GB显存) RTX 4080 (16GB显存) 内存 16GB 32GB 存储 50GB可用空间 SSD固态硬盘 系统 Windows 10 / macOS 12 / Ubuntu 20.04 Windows 11 二、部署流程 2.1安装Ollama框架 Ollama是什么? Ollama是一个开源的LLM(大语言模型)服务工具,用于简化在本地运行大模型语言,降低使用大模型语言的门槛,使得大语言模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新的大语言模型,包括Llama3、Phi3、Mistral、Gemma等开源的大语言模型。 2.1.1下载安装包访问Ollama官网选择对应的系统版本进行下载
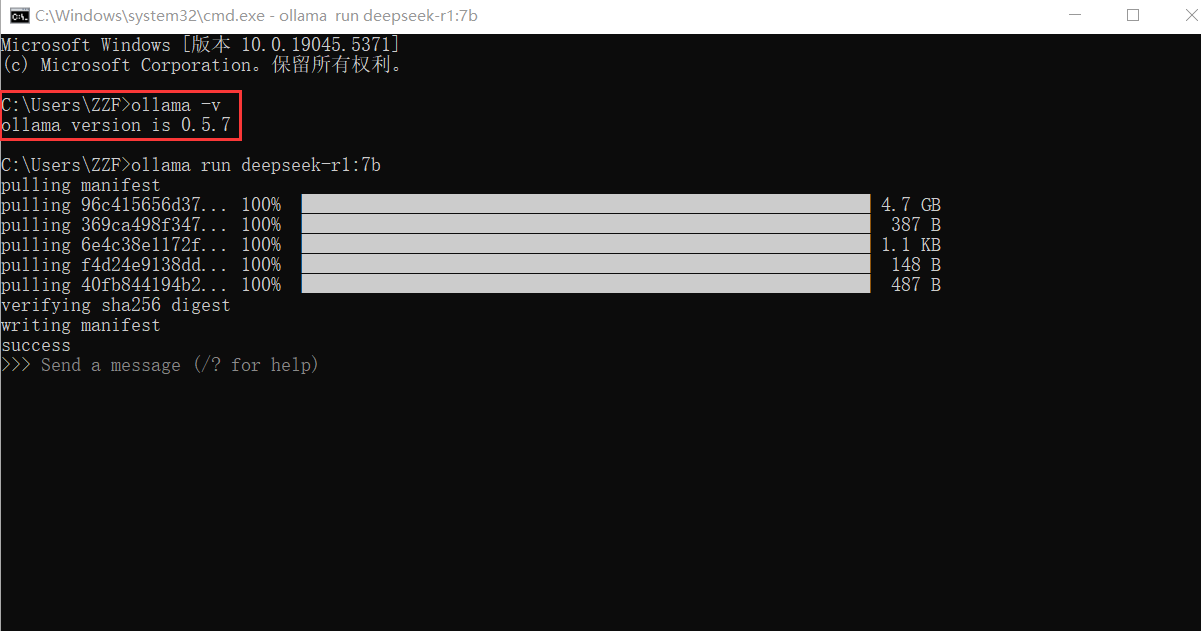
下载完成后安装,等待安装完成即可。 2.1.2验证Ollama是否安装成功Win+R在打开cmd在终端输入ollama -v命令查看ollama版本:
如果可以正常出现Ollama的版本号,则说明Ollama已安装成功。 2.2选择合适的DeepSeek版本Ollama安装成功后,进入DeepSeek官网,根据自己的电脑配置选择适合于自己配置的大模型版本。 DeepSeek 不同参数版本介绍: 模型参数规模 CPU推荐 GPU推荐 内存推荐 磁盘推荐1.5b 4核以上 (Intel i5 / AMD Ryzen 5) 可选,入门级 GPU (如 NVIDIA GTX 1650, 4GB 显存) 8GB 10GB 以上 SSD 7b 6核以上 (Intel i7 / AMD Ryzen 7) 中端 GPU (如 NVIDIA RTX 3060, 12GB 显存) 16GB 20GB 以上 SSD 14b 8核以上 (Intel i9 / AMD Ryzen 9) 高端 GPU (如 NVIDIA RTX 3090, 24GB 显存) 32GB 50GB 以上 SSD 32b 12核以上 (Intel Xeon / AMD Threadripper) 高性能 GPU (如 NVIDIA A100, 40GB 显存) 64GB 100GB 以上 SSD 70b 16核以上 (服务器级 CPU) 多 GPU 并行 (如 2x NVIDIA A100, 80GB 显存) 128GB 200GB 以上 SSD 671b 服务器级 CPU (如 AMD EPYC / Intel Xeon) 多 GPU 集群 (如 8x NVIDIA A100, 320GB 显存) 256GB 或更高 1TB 以上 NVMe SSD 选择适合自己电脑的参数后,下载DeepSeek到本地,例如我个人选择7b这个参数,运行以下代码: ollama run deepseek-r1:7b
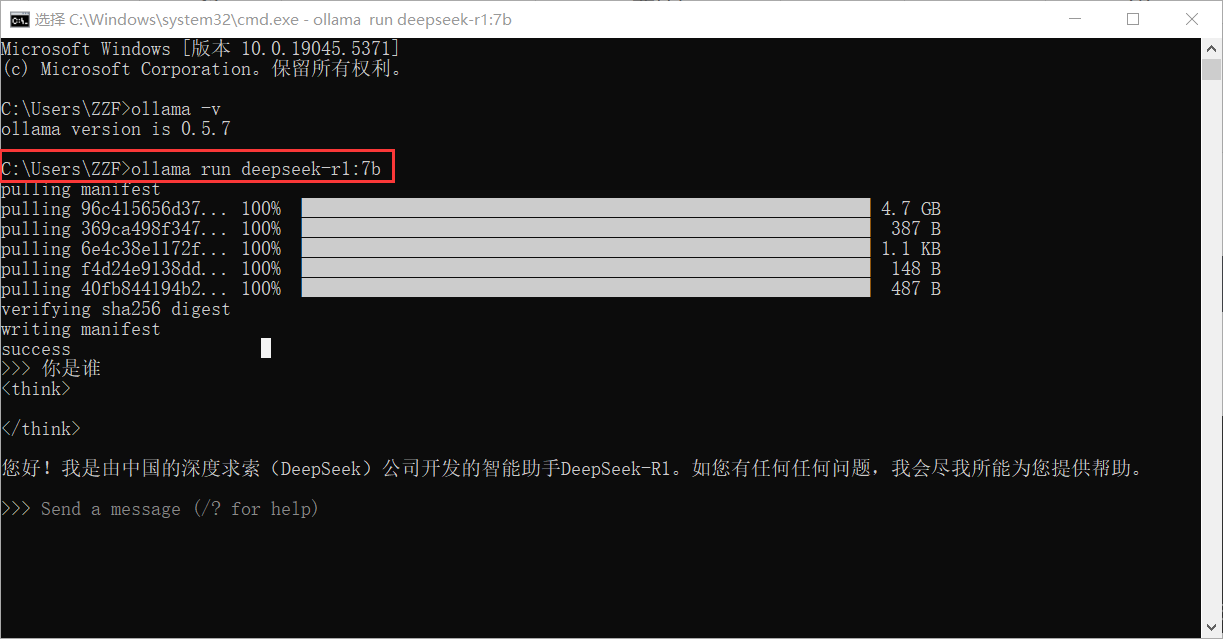
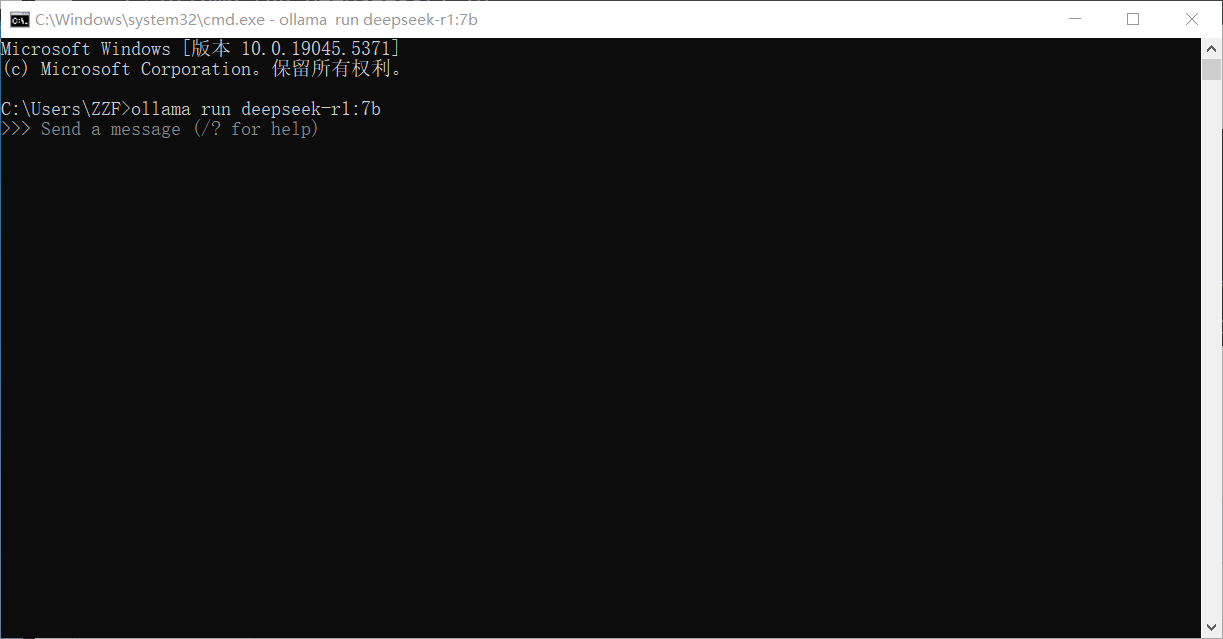
点击回车开始下载,等待下载完成后,就可以在本地终端中使用大语言模型了,如图所示:
关闭终端后,再次打开cmd不会进入deepseek对话,需要执行命令行ollama run deepseek-r1:7b,但是,不会再次进行下载,而是直接进入对话框。
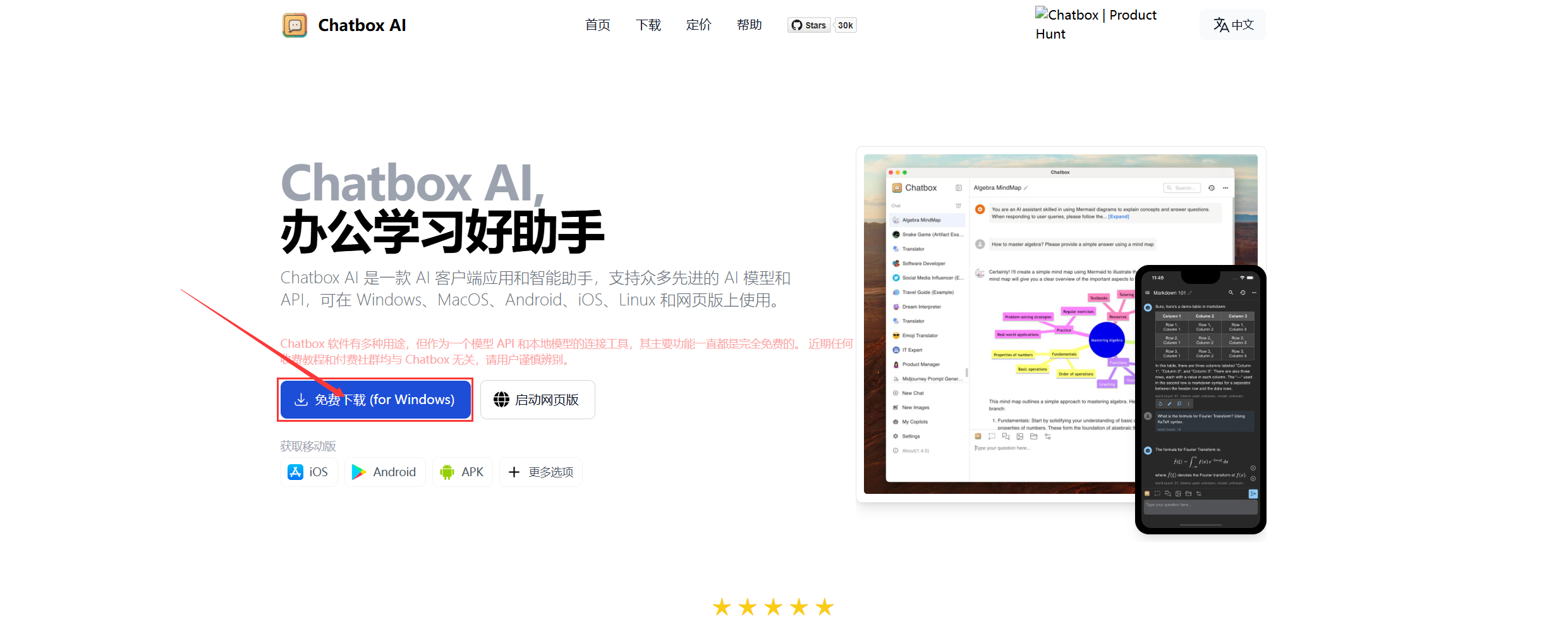
如果你觉得每次都需要使用命令行打开太麻烦了,那么可以借助通用AI客户端工具来实现。简单来说就是借助第三方UI工具更加方便地和deepseek进行交互。我是用的是Chatbox 3.Chatbox使用方法首先进入ChatBox官网下载安装包
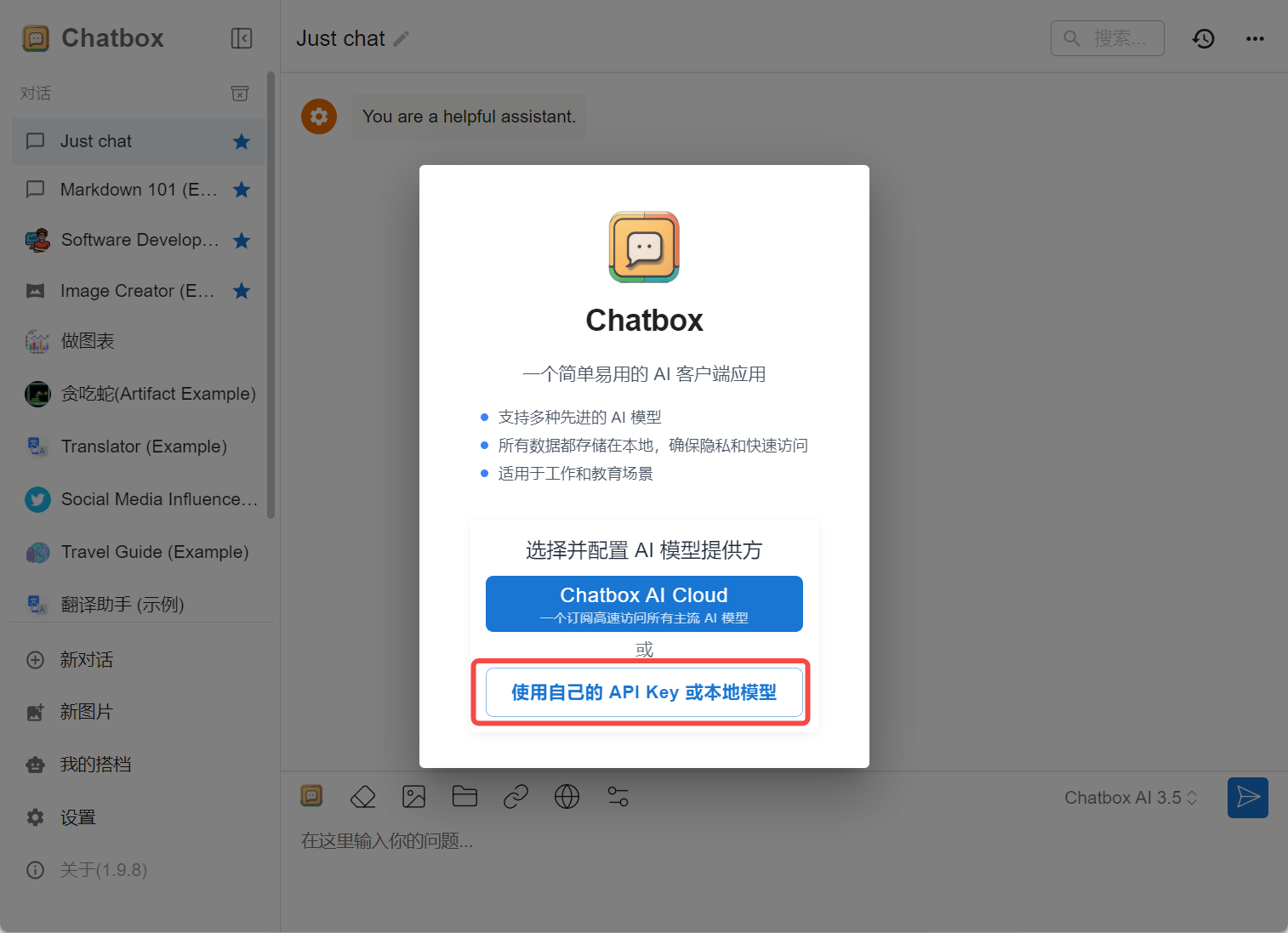
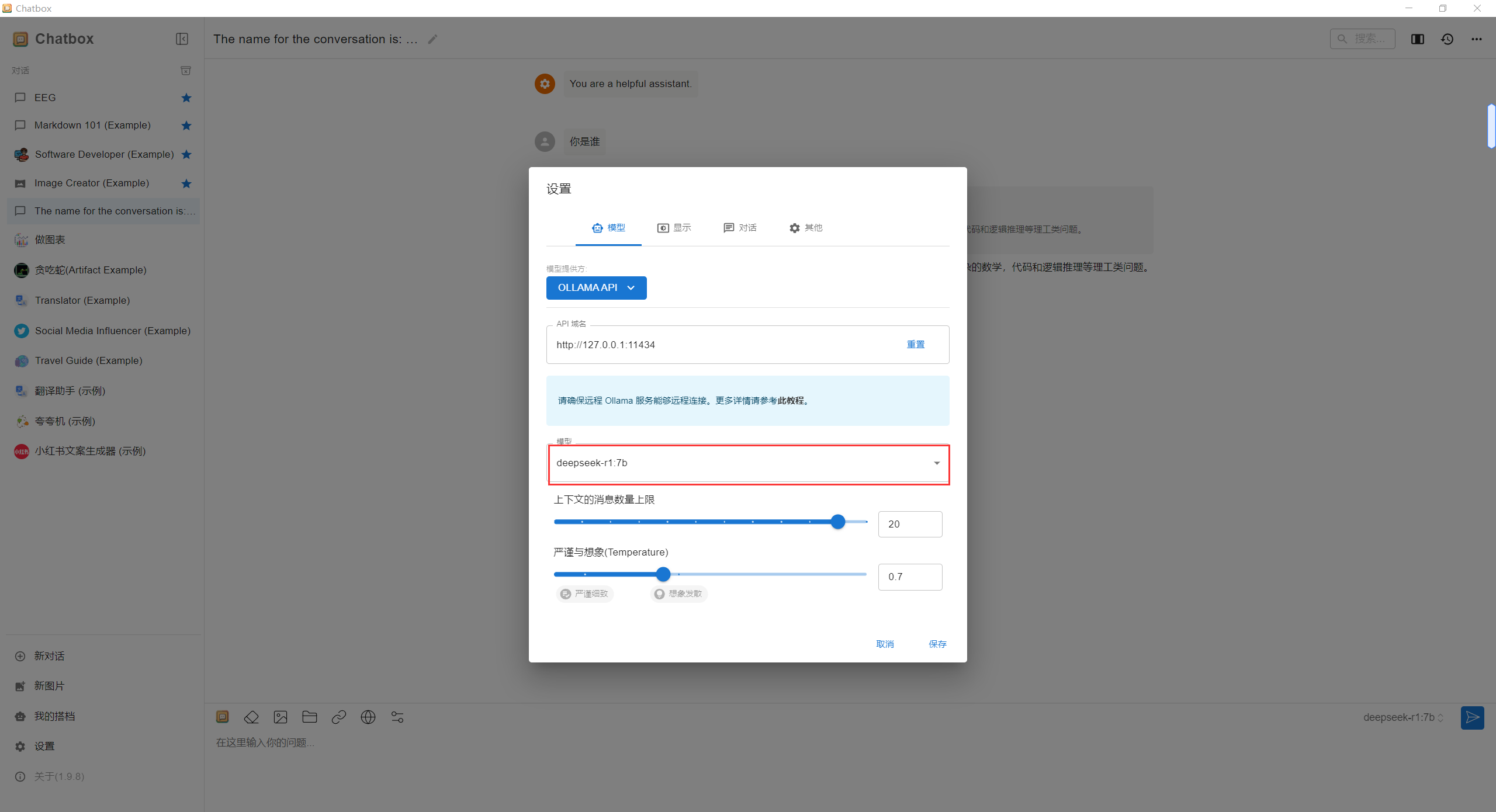
安装成功后运行Chatbox,将DeepSeek配置到Chatbox。如下图所示:
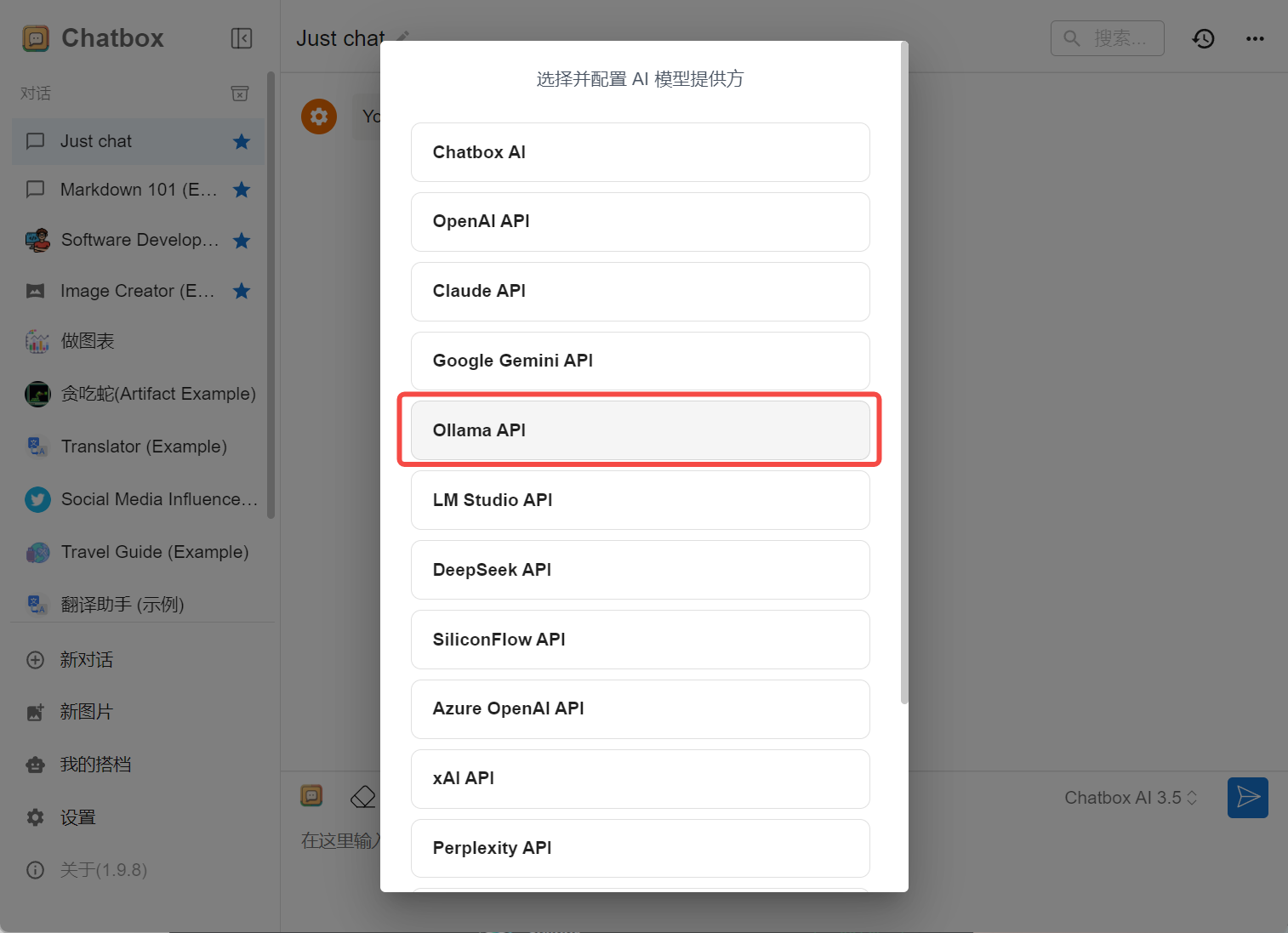
选择并配置AI模型提供方,这里选择Ollama AI
选择DeepSeek模型
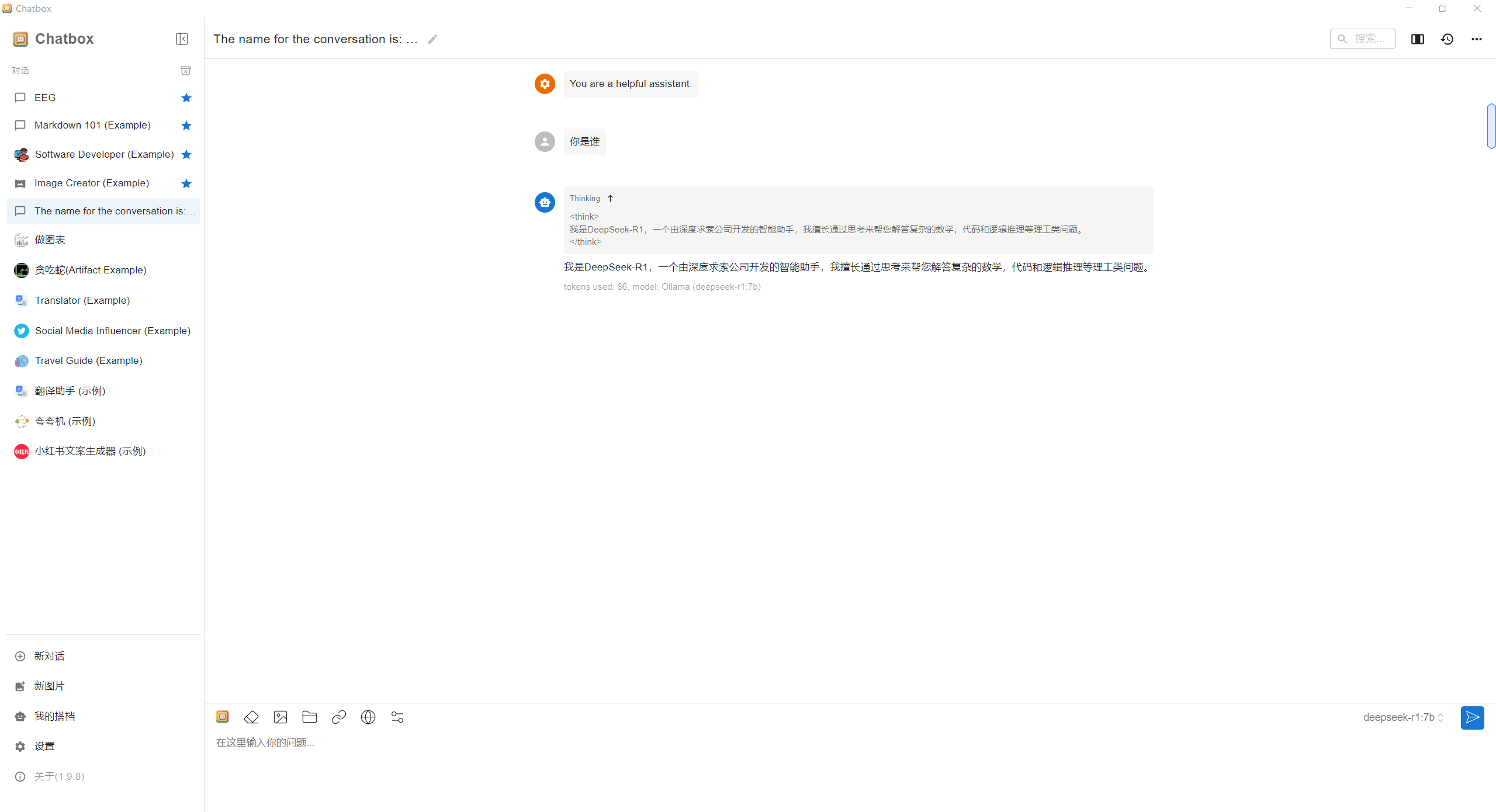
完成以上步骤后,就可以在Chatbox中和本地DeepSeek模型进行交互了。
注意:部署到本地后,无法进行联网搜索,但是上传文件是可以实现的。 (责任编辑:) |