|
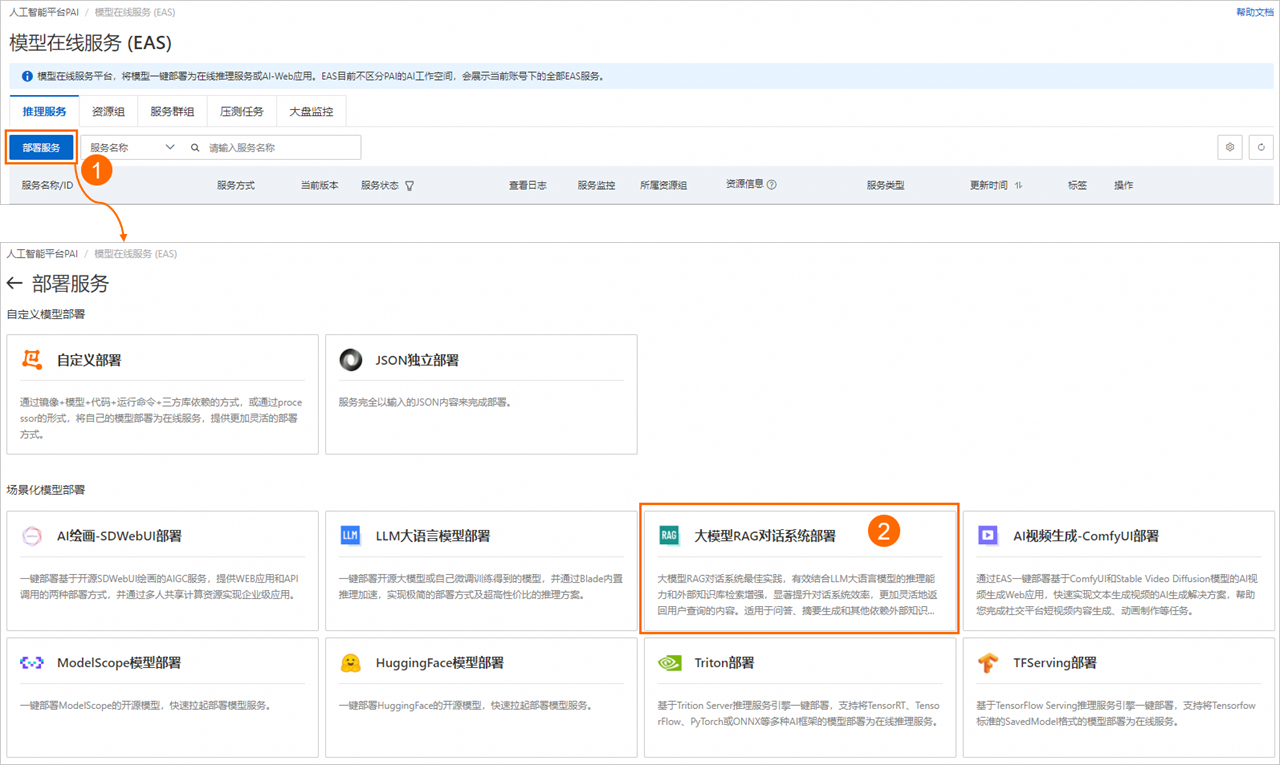
RAG(Retrieval-Augmented Generation,检索增强生成)技术通过从外部知识库检索相关信息,并将其与用户输入合并后传入大语言模型(LLM),从而增强模型在私有领域知识问答方面的能力。EAS提供场景化部署方式,支持灵活选择大语言模型和向量检索库,实现RAG对话系统的快速构建与部署。本文为您介绍如何部署RAG对话系统服务以及如何进行模型推理验证。 步骤一:部署RAG服务 登录,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。 在模型在线服务(EAS)页面,单击部署服务,然后在场景化模型部署区域,单击大模型RAG对话系统部署。
在部署大模型RAG对话系统页面,配置参数后单击部署。当服务状态变为运行中时,表示服务部署成功(服务部署时长通常约为5分钟,具体时长可能因模型参数量或其他因素略有差异,请耐心等待)。关键参数说明如下。 基本信息 参数 描述 版本选择 支持部署以下两种版本: LLM一体化部署:将大语言模型(LLM)服务和RAG服务部署在同一服务内。 LLM分离式部署:仅部署RAG服务。但在RAG服务内,您可以自由更换和连接LLM服务,灵活性更高。 模型类别 当版本选择LLM一体化部署时,您需要选择要部署的大语言模型(LLM)。您可以根据具体使用场景选择相应的开源模型。 资源信息 参数 描述 部署资源 在选择LLM一体化部署版本时,系统会根据所选模型类别,自动匹配适合的资源规格。更换为其他资源规格,可能会导致模型服务无法正常启动。 在选择LLM分离式部署版本时,建议选择8核以上的CPU资源和16 GB以上的内存,推荐使用ecs.g6.2xlarge、ecs.g6.4xlarge等机型。 向量检索库设置 RAG支持通过Faiss(Facebook AI Similarity Search)、Elasticsearch、Milvus、Hologres、OpenSearch或RDS PostgreSQL构建向量检索库。根据您的场景需要,任意选择一种版本类型,作为向量检索库。 FAISS使用Faiss构建本地向量库,无需购买线上向量库产品,免去了线上开通向量库产品的复杂流程,更轻量易用。 参数 描述 版本类型 选择FAISS。 OSS地址 选择当前地域下已创建的OSS存储路径,用来存储上传的知识库文件。如果没有可选的存储路径,您可以参考控制台快速入门进行创建。 说明 如果您选择使用自持微调模型部署服务,请确保所选的OSS存储路径不与自持微调模型所在的路径重复,以避免造成冲突。 ElasticSearch 配置阿里云ElasticSearch实例的连接信息。关于如何创建ElasticSearch实例及准备配置项,请参见。 参数 描述 版本类型 选择Elasticsearch。 私网地址/端口 配置Elasticsearch实例的私网地址和端口,格式为<私网地址>:<私网端口>。如何获取Elasticsearch实例的私网地址和端口号,请参见查看实例的基本信息。 索引名称 输入新的索引名称或已存在的索引名称。对于已存在的索引名称,索引结构应符合PAI-RAG要求,例如您可以填写之前通过EAS部署RAG服务时自动创建的索引。 账号 配置创建Elasticsearch实例时配置的登录名,默认为elastic。 密码 配置创建Elasticsearch实例时配置的登录密码。如果您忘记了登录密码,可重置实例访问密码。 Milvus 配置Milvus实例的连接信息。关于如何创建Milvus实例及准备配置项,请参见。 参数 描述 版本类型 选择Milvus。 访问地址 配置为Milvus实例内网地址。您可以前往阿里云Milvus控制台的实例详情页面的访问地址区域进行查看。 代理端口 配置为Milvus实例的Proxy Port,默认为19530。您可以前往阿里云Milvus控制台的实例详情页面的访问地址区域进行查看。 账号 配置为root。 密码 配置为创建Milvus实例时,您自定义的root用户的密码。 数据库名称 配置为数据库名称,例如default。创建Milvus实例时,系统会默认创建数据库default,您也可以手动创建新的数据库,具体操作,请参见管理Databases。 Collection名称 输入新的Collection名称或已存在的Collection名称。对于已存在的Collection,Collection结构应符合PAI-RAG要求,例如您可以填写之前通过EAS部署RAG服务时自动创建的Collection。 Hologres 配置为Hologres实例的连接信息。如果未开通Hologres实例,可参考购买Hologres进行操作。 参数 描述 版本类型 选择Hologres。 调用信息 配置为指定VPC的host信息。进入的实例详情页,在网络信息区域单击指定VPC后的复制,获取域名:80前的host信息。 数据库名称 配置为Hologres实例的数据库名称。如何创建数据库,详情请参见创建数据库。 账号 配置为已创建的自定义用户账号。具体操作,请参见,其中选择成员角色选择实例超级管理员(SuperUser)。 密码 配置为已创建的自定义用户的密码。 表名称 输入新的表名称或已存在的表名称。对于已存在的表名称,表结构应符合PAI-RAG要求,例如可以填写之前通过EAS部署RAG服务自动创建的Hologres表。 OpenSearch 配置为OpenSearch向量检索版实例的连接信息。关于如何创建OpenSearch实例及准备配置项,请参见。 参数 描述 版本类型 选择OpenSearch。 访问地址 配置为OpenSearch向量检索版实例的公网访问地址。您需要为OpenSearch向量检索版实例开通公网访问功能,具体操作,请参见。 实例id 在OpenSearch向量检索版实例列表中获取实例ID。 用户名 配置为创建OpenSearch向量检索版实例时,输入的用户名和密码。 密码 表名称 配置为准备OpenSearch向量检索版实例时创建的索引表名称。如何准备索引表,请参见。 RDS PostgreSQL 配置为RDS PostgreSQL实例数据库的连接信息。关于如何创建RDS PostgreSQL实例及准备配置项,请参见。 参数 描述 版本类型 选择RDS PostgreSQL。 主机地址 配置为RDS PostgreSQL实例的内网地址,您可以前往云数据库RDS PostgreSQL控制台页面,在RDS PostgreSQL实例的数据库连接页面进行查看。 端口 默认为5432,请根据实际情况填写。 数据库 配置为已创建的数据库名称。如何创建数据库和账号,请参见创建账号和数据库,其中: 创建账号时,账号类型选择高权限账号。 创建数据库时,授权账号选择已创建的高权限账号。 表名称 自定义配置数据库表名称。 账号 配置为已创建的高权限账号和密码。如何创建高权限账号,请参见创建账号和数据库,其中账号类型选择高权限账号。 密码 专有网络 参数 描述 专有网络(VPC) 在部署RAG服务时,如果选择LLM分离式部署,需确保RAG服务能正常访问LLM服务。具体网络要求如下: 通过公网访问LLM服务:需在此处配置具有公网访问能力的专有网络,详情请参见。 通过内网地址访问LLM服务:RAG服务和LLM服务需使用相同的专有网络。 如果您需要使用阿里云百炼模型或者使用联网搜索进行问答,需配置具有公网访问能力的专有网络,详情请参见。 向量检索库的网络要求: 交换机 安全组名称 步骤二:WebUI页面调试 RAG服务部署成功后,单击服务方式列下的查看Web应用,启动WebUI页面。 请按照以下操作步骤,在WebUI页面上传企业知识库文件并对问答效果进行调试。 1、向量检索库与大语言模型设置在Settings页签,您可以修改Embedding相关参数以及使用的大语言模型。建议直接使用默认配置。 说明 使用dashscope,您需要给EAS,并配置阿里云百炼的API Key。阿里云百炼模型调用需单独计费,请参见阿里云百炼计费项说明。 Embedding Dimension 输出向量维度。维度的设置对模型的性能有直接影响。在您选择Embedding模型后,系统将自动配置Embedding维度,无需手动操作。 Embedding Batch Size 批处理大小。 Large Language Model相关参数说明 当版本选择LLM分离部署时,您需要参照LLM大语言模型部署来部署大语言模型服务,然后单击LLM服务名称,在基本信息区域单击查看调用信息,获取服务访问地址和Token。 说明 使用公网地址连接LLM服务:RAG服务需绑定具有公网访问能力的专有网络。 使用VPC地址连接LLM服务:RAG服务与LLM服务必须在同一个专有网络内。
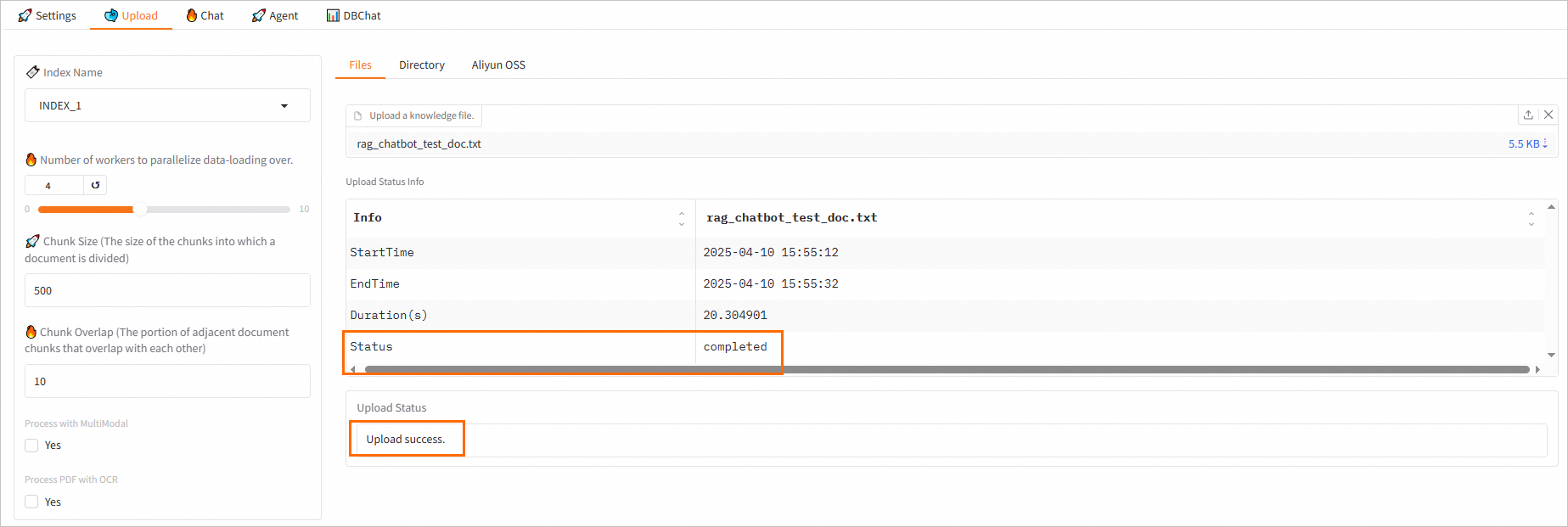
参数 描述 LLM Base URL 当使用LLM分离部署时,配置为已获取的LLM服务的访问地址和Token。 当使用LLM一体化部署时,系统已默认配置该参数,无需修改。 API Key Model name 在部署大语言模型(LLM)时,如果您选择了加速部署-vLLM模式,请务必填写具体的模型名称,例如qwen2-72b-instruct。对于其他部署模式,则只需将模型名称设置为default即可。 2、上传知识库文件 在Upload页签,您可以上传知识库文件,系统会自动按照PAI-RAG格式将文件存储到向量检索库。对于同名知识库文件,除了FAISS外,其他向量检索库将会覆盖原有文件。支持的文件类型为.html、.htm、.txt、.pdf、.pptx、.md、Excel(.xlsx或.xls)、.jsonl、.jpeg、.jpg、.png、.csv或Word(.docx),例如rag_chatbot_test_doc.txt。支持的上传方式如下: 从本地上传文件(支持多文件上传)或对应目录(Files或Directory页签) 从OSS上传(Aliyun OSS页签) 重要 上传前,请确保在Settings页签的Large Language Model区域,选中Use OSS Storage并完成相关参数的配置。 下图状态表示知识库文件上传成功:
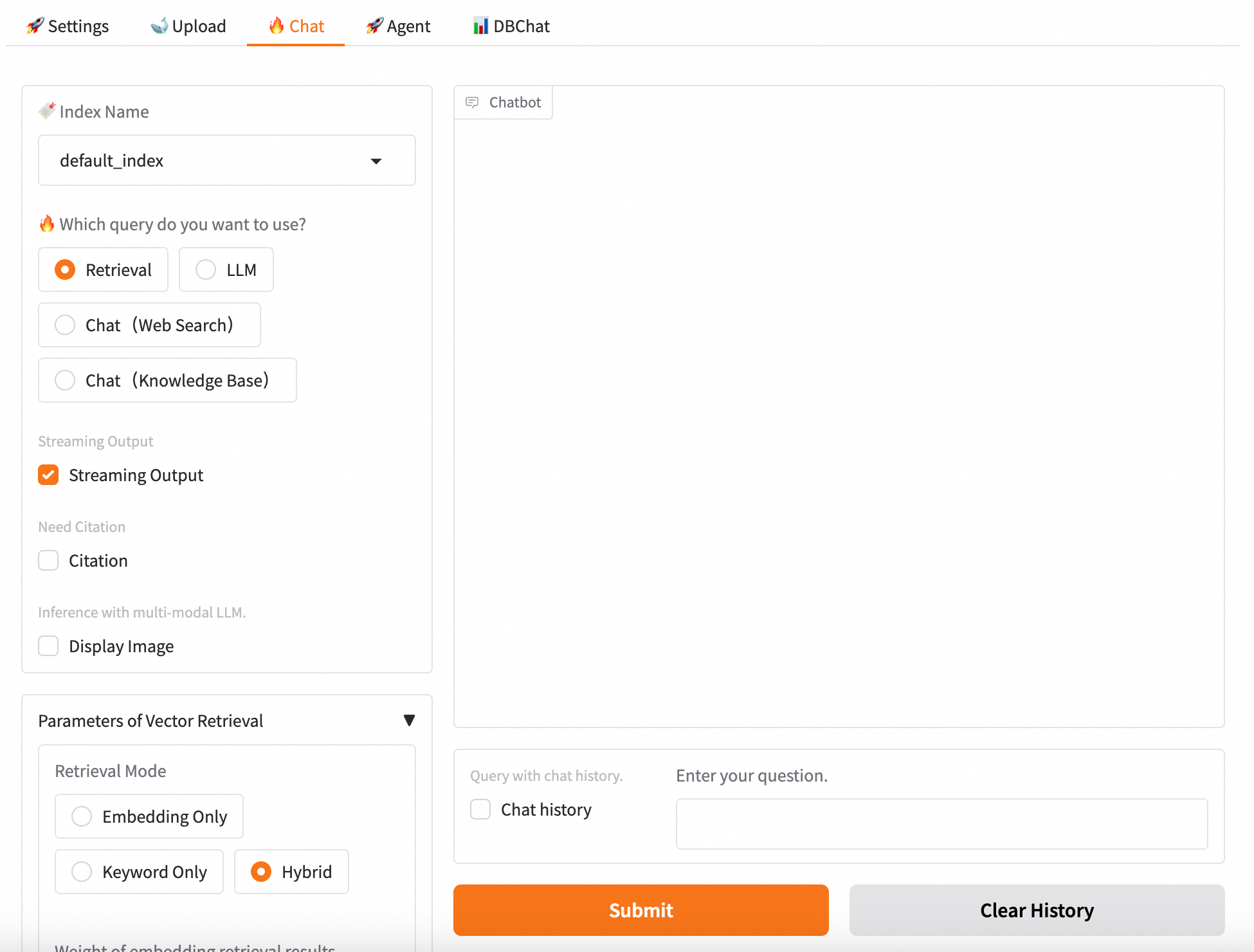
您可以在上传之前修改多并发控制和语义分块参数,参数说明如下: 参数 描述 Number of workers to parallelize data-loading over 多并发控制参数,默认为4,表示系统支持同时启动4个进程来上传文件。建议将并发数设置为的大小。例如,当前GPU显存为24 GB,则并发数可以设置为4。 Chunk Size 指定每个文本分块的大小,单位为字节,默认为500。 Chunk Overlap 表示相邻分块之间的重叠量,默认为10。 Process with MultiModal 使用多模态模型处理,可以处理pdf、word、md文件的图片。如果您选择了使用多模态LLM,请打开此开关。 Process PDF with OCR 使用OCR模式解析PDF文件。 3、模型推理验证 在Chat页签选择使用的知识库索引(Index Name),配置问答策略,并进行问答测试。支持以下4种问答策略: Retrieval:直接从向量数据库中检索并返回Top K条相似结果。 LLM:直接使用LLM回答。 Chat(Web Search):根据用户提问自动判断是否需要联网搜索,如果联网搜索,将搜索结果和用户问题一并输入大语言模型服务。使用联网搜索需要给EAS。 Chat(Knowledge Base):将向量数据库检索返回的结果与用户问题合并填充至已选择的Prompt模板中,一并输入大语言模型服务进行处理,从中获取问答结果。
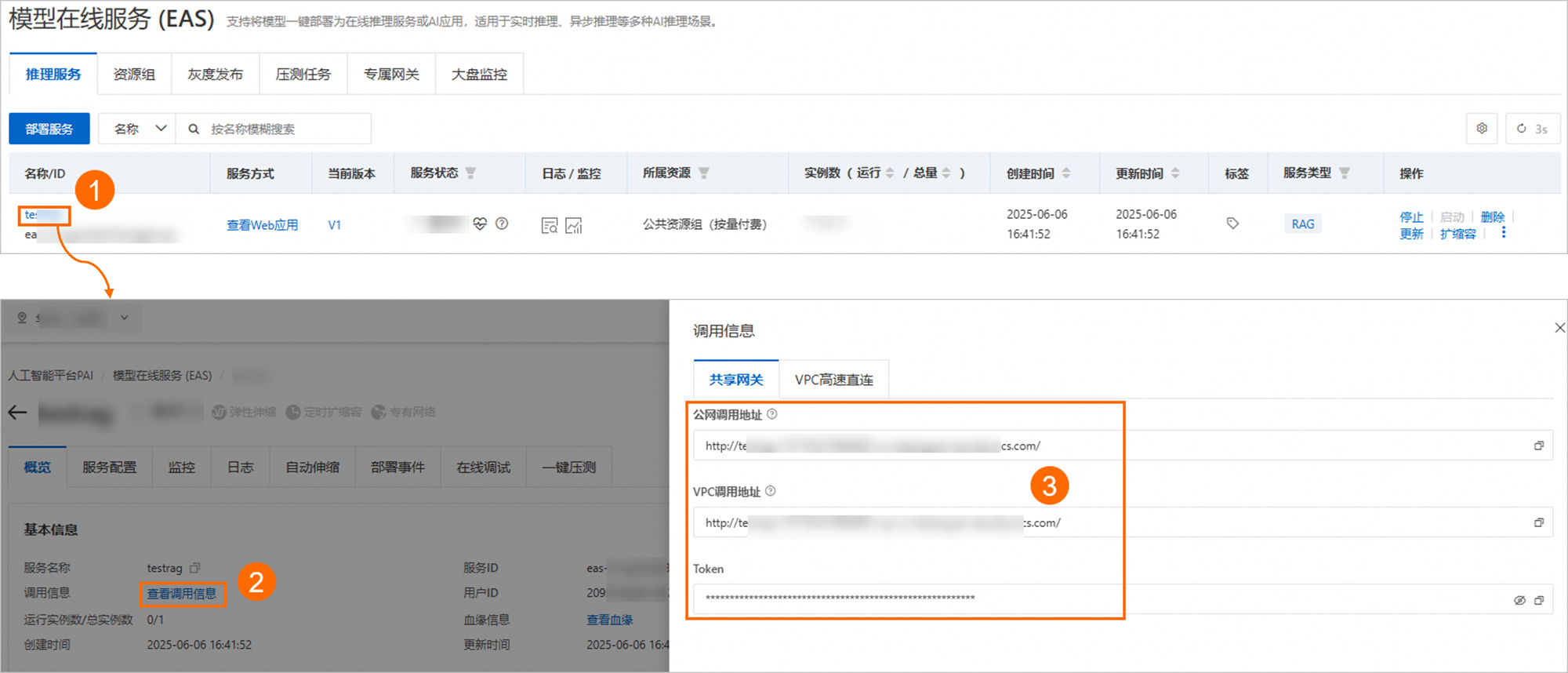
更多推理参数说明如下: 通用参数 参数 说明 Streaming Output 选中Streaming Output后,系统将以流式方式输出结果。 Need Citation 回答中是否需要给出引用。 Inference with multi-modal LLM 使用多模态大语言模型时是否展示图片。 向量检索相关参数 Retrieval Mode:支持以下三种检索方式: Embedding Only:向量数据库检索召回。在大多数复杂场景下,该方式表现较好,尤其适合处理语义相似性和上下文相关的查询。 Keyword Only:关键词检索召回。在某些语料稀缺的垂直领域或需要精确匹配的场景中,该方式更具优势。PAI也提供了BM25等关键词检索召回算法来完成稀疏检索召回操作。通过计算用户查询与知识文档的关键词重叠度进行检索,具有简单高效的特点。 Hybrid:向量数据库和关键词检索多路召回融合。为了综合两种召回方式的优势,PAI支持通过倒数排序融合(Reciprocal Rank Fusion, RRF)算法对每个文档在不同召回方法中的排名进行加权求和,以此计算融合后的总分数,从而提升整体检索的准确性和效率。当Retrieval Mode选择Hybrid模式时,PAI默认使用RRF算法完成多路召回融合。 支持配置以下向量检索参数: 参数 描述 Text Top K 召回Top-K条最相关的文本片段。取值为0~100。 Image Top K 召回Top-K个最相关的图像。取值为0~10。 Similarity Score Threshold 相似度分数阈值。分数越大,表示返回的内容越相似。 Reranker Type 选择重排序类型: 无重排序 基于模型的重排序:选择重排序模型,对第一次召回的Top K条结果进行精度更高的重排序操作,以获得相关度更高、更准确的检索结果。 说明 首次使用时,加载模型可能需要较长时间,请根据需要进行选择。 当ReTrieval Model选择Hybrid时,可通过配置以下向量检索参数,来调整向量检索和关键字检索的比例,从而优化混合检索效果。 Weight of embedding retrieval results 向量检索权重。 Weight of keyword retrieval results 关键字检索权重。 联网搜索相关 参数 说明 bing:配置Bing搜索。 Bing API Key 用于访问Bing搜索。如何获取Bing API Key,请参见Bing Web Search API。 Search Count 搜索的网页数量,默认为10。 Language 搜索语言,支持选择zh-CN(中文)和en-US(英文)。 aliyun:配置阿里云通用搜索服务。如何开通阿里云搜索服务,请参见联网搜索开通说明。 Search Count 当QPS限制为1时,SearchCount的最大值不能超过10。 AccessKey ID 请填写已获取的AccessKey ID。 AccessKey Secret 请填写已获取的AccessKey Secret。 LLM相关 Temperature :控制生成内容的随机性。温度值越低,输出结果也相对固定;而温度越高,输出结果则更具多样性和创造性。 步骤三:API调用以下内容介绍了RAG常用功能的API调用方法。如需了解更多功能的API调用方法(如管理知识库索引、更新RAG服务配置等),请参见RAG API接口说明。 重要 查询和上传API均可以指定index_name来切换知识库,当index_name参数省略时,默认为default_index。详情请参见。 获取调用信息单击RAG服务名称,进入服务详情页面。 在基本信息区域,单击查看调用信息。 在调用信息对话框,获取服务访问地址和Token。 说明 您可以选择使用公网地址或VPC内网地址: 使用公网地址,调用客户端需支持访问公网。 使用内网地址:调用客户端必须与RAG服务位于同一个专有网络内。 上传知识库文件支持通过API上传本地的知识库文件。根据上传接口返回的task_id可以查询文件上传任务的状态。 以下示例中,<EAS_SERVICE_URL>替换为RAG服务的访问地址;<EAS_TOKEN>替换为RAG服务的Token。获取方式详情请参见。 上传单个文件 # <EAS_TOKEN>和<EAS_SERVICE_URL>需分别替换为服务Token和访问地址。 # "-F 'files=@"后的路径需替换为您的文件路径。 # index_name配置为您的知识库索引名称。 curl -X 'POST' <EAS_SERVICE_URL>/api/v1/upload_data \ -H 'Authorization: <EAS_TOKEN>' \ -H 'Content-Type: multipart/form-data' \ -F 'files=@example_data/paul_graham/paul_graham_essay.txt' \ -F 'index_name=default_index'上传多份文件,可以使用多个-F 'files=@path'参数,每个参数对应一个要上传的文件,示例如下: # <EAS_TOKEN>和<EAS_SERVICE_URL>需分别替换为服务Token和访问地址。 # “-F 'files=@”后的路径需替换为您的文件路径。 # index_name配置为您的知识库索引名称。 curl -X 'POST' <EAS_SERVICE_URL>/api/v1/upload_data \ -H 'Authorization: <EAS_TOKEN>' \ -H 'Content-Type: multipart/form-data' \ -F 'files=@example_data/paul_graham/paul_graham_essay.txt' \ -F 'files=@example_data/another_file1.md' \ -F 'files=@example_data/another_file2.pdf' \ -F 'index_name=default_index'查询上传任务状态 # <EAS_TOKEN>和<EAS_SERVICE_URL>需分别替换为服务Token和访问地址。 # task_id配置为“上传知识库文件”返回的task_id。 curl -X 'GET' '<EAS_SERVICE_URL>/api/v1/get_upload_state?task_id=2c1e557733764fdb9fefa0635389****' -H 'Authorization: <EAS_TOKEN>'单轮对话请求cURL 命令注意:以下示例中,<service_url>替换为RAG服务的访问地址;<service_token>替换为RAG服务的Token。获取方式详情请参见。 Retrieval:api/v1/query/retrieval curl -X 'POST' '<service_url>api/v1/query/retrieval' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平台PAI?"}'LLM:/api/v1/query/llm curl -X 'POST' '<service_url>api/v1/query/llm' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平台PAI?"}'支持添加其他可调推理参数,例如{"question":"什么是人工智能平台PAI?", "temperature": 0.9}。 Chat(Knowledge Base):api/v1/query curl -X 'POST' '<service_url>api/v1/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平台PAI?"}'支持添加其他可调推理参数,例如{"question":"什么是人工智能平台PAI?", "temperature": 0.9}。 Chat(Web Search):api/v1/query/search curl --location '<service_url>api/v1/query/search' \ --header 'Authorization: <service_token>' \ --header 'Content-Type: application/json' \ --data '{"question":"中国电影票房排名", "stream": true}'Python脚本注意:以下示例中,SERVICE_URL配置为RAG服务的访问地址;Authorization配置为RAG服务的Token。获取方式详情请参见。 import requests SERVICE_URL = 'http://xxxx.****.cn-beijing.pai-eas.aliyuncs.com/' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', 'Authorization': 'MDA5NmJkNzkyMGM1Zj****YzM4M2YwMDUzZTdiZmI5YzljYjZmNA==', } def test_post_api_query(url): data = { "question":"什么是人工智能平台PAI?" } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = dict(response.json()) print(f"======= Question =======\n {data['question']}") if 'answer' in ans.keys(): print(f"======= Answer =======\n {ans['answer']}") if 'docs' in ans.keys(): print(f"======= Retrieved Docs =======\n {ans['docs']}\n\n") # LLM test_post_api_query(SERVICE_URL + 'api/v1/query/llm') # Retrieval test_post_api_query(SERVICE_URL + 'api/v1/query/retrieval') # Chat(Knowledge Base) test_post_api_query(SERVICE_URL + 'api/v1/query')多轮对话请求LLM和Chat(Knowledge Base)支持发送多轮对话请求,代码示例如下: cURL命令注意:以下示例中,<service_url>替换为RAG服务的访问地址;<service_token>替换为RAG服务的Token。获取方式详情请参见。 以RAG对话为例: # 发送请求。 curl -X 'POST' '<service_url>api/v1/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平台PAI?"}' # 传入上述请求返回的session_id(对话历史会话唯一标识),传入session_id后,将对话历史进行记录,调用大模型将自动携带存储的对话历史。 curl -X 'POST' '<service_url>api/v1/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "它有什么优势?","session_id": "ed7a80e2e20442eab****"}' # 传入chat_history(用户与模型的对话历史),list中的每个元素是形式为{"user":"用户输入","bot":"模型输出"}的一轮对话,多轮对话按时间顺序排列。 curl -X 'POST' '<service_url>api/v1/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question":"它有哪些功能?", "chat_history": [{"user":"PAI是什么?", "bot":"PAI是阿里云的人工智能平台......"}]}' # 同时传入session_id和chat_history,会用chat_history对存储的session_id所对应的对话历史进行追加更新。 curl -X 'POST' '<service_url>api/v1/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question":"它有哪些功能?", "chat_history": [{"user":"PAI是什么?", "bot":"PAI是阿里云的人工智能平台......"}], "session_id": "1702ffxxad3xxx6fxxx97daf7c"}'Python注意:以下示例中,SERVICE_URL配置为RAG服务的访问地址;Authorization配置为RAG服务的Token。获取方式详情请参见。 import requests SERVICE_URL = 'http://xxxx.****.cn-beijing.pai-eas.aliyuncs.com' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', 'Authorization': 'MDA5NmJkN****jNlMDgzYzM4M2YwMDUzZTdiZmI5YzljYjZmNA==', } def test_post_api_query_with_chat_history(url): # Round 1 query data = { "question": "什么是人工智能平台PAI?" } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = dict(response.json()) print(f"=======Round 1: Question =======\n {data['question']}") if 'answer' in ans.keys(): print(f"=======Round 1: Answer =======\n {ans['answer']} session_id: {ans['session_id']}") if 'docs' in ans.keys(): print(f"=======Round 1: Retrieved Docs =======\n {ans['docs']}") # Round 2 query data_2 = { "question": "它有什么优势?", "session_id": ans['session_id'] } response_2 = requests.post(url, headers=headers, json=data_2) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans_2 = dict(response_2.json()) print(f"=======Round 2: Question =======\n {data_2['question']}") if 'answer' in ans.keys(): print(f"=======Round 2: Answer =======\n {ans_2['answer']} session_id: {ans_2['session_id']}") if 'docs' in ans.keys(): print(f"=======Round 2: Retrieved Docs =======\n {ans['docs']}") print("\n") # LLM test_post_api_query_with_chat_history(SERVICE_URL + "api/v1/query/llm") # Chat(Knowledge Base) test_post_api_query_with_chat_history(SERVICE_URL + "api/v1/query")注意事项本实践受制于LLM服务的最大Token数量限制,旨在帮助您体验RAG对话系统的基本检索功能: 该对话系统受制于LLM服务的服务器资源大小以及默认Token数量限制,能支持的对话长度有限。 如果无需进行多轮对话,建议您关闭with chat history功能,这样能有效减少达到限制的可能性。 WebUI操作方式:在RAG服务WebUI页面的Chat页签,去勾选Chat history复选框。
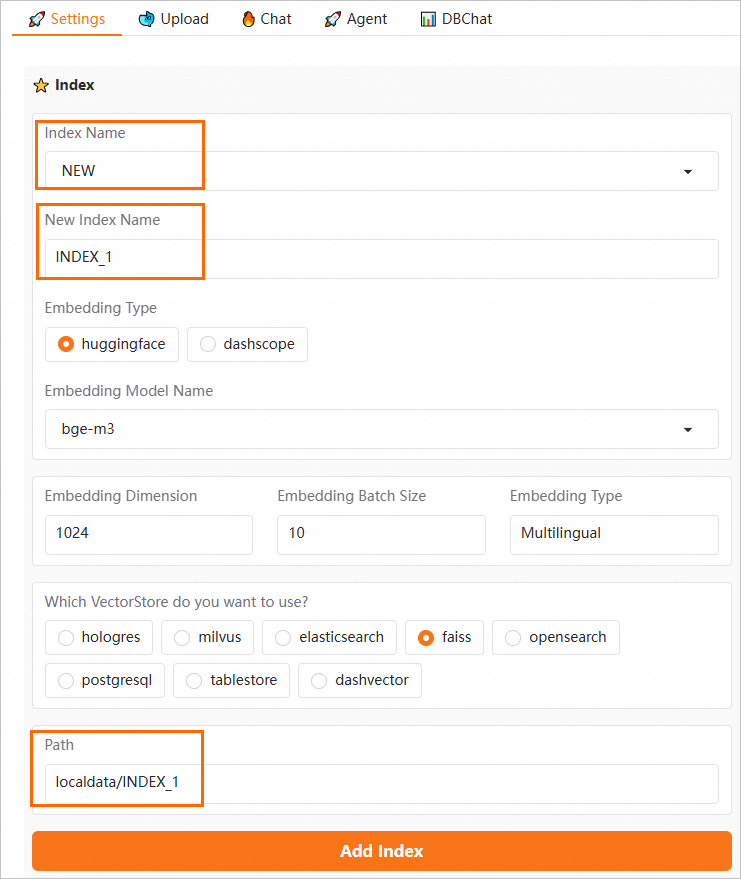
当不同部门或个人使用各自独立的知识库时,可以通过以下方法实现数据的有效隔离: 在WebUI页面的Settings页签,配置以下参数,然后单击Add Index。 Index Name:选择NEW。 New Index Name:自定义新的索引名称。例如INDEX_1。 Path:当选择Faiss作为VectorStore时,需要同步更新Path路径,确保路径末尾的索引名称与新的索引名称一致。
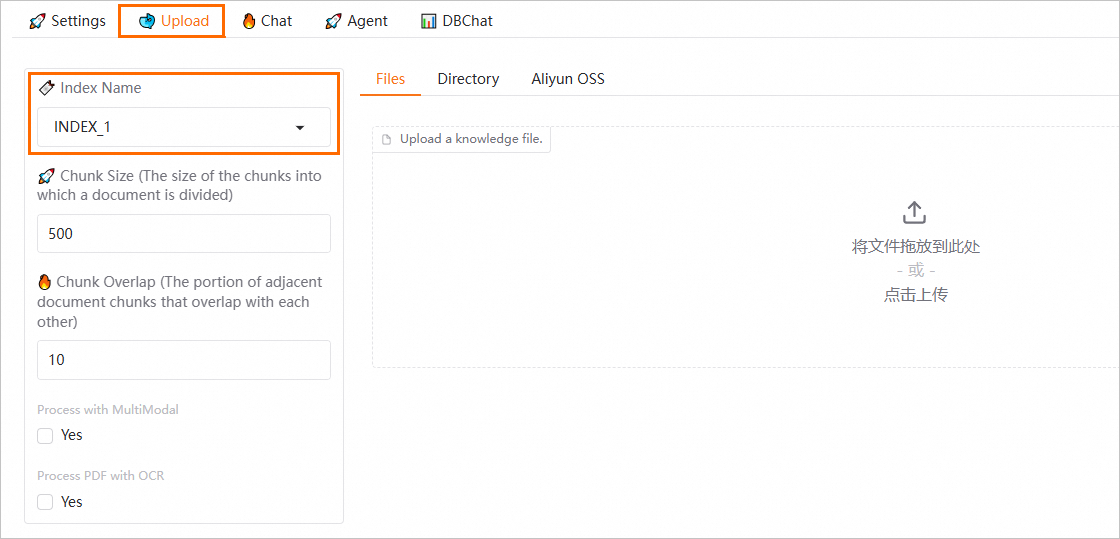
在Upload页签上传知识库文件时,您可以选择Index Name(索引名称)。上传后,文件将被保存到所选索引下。
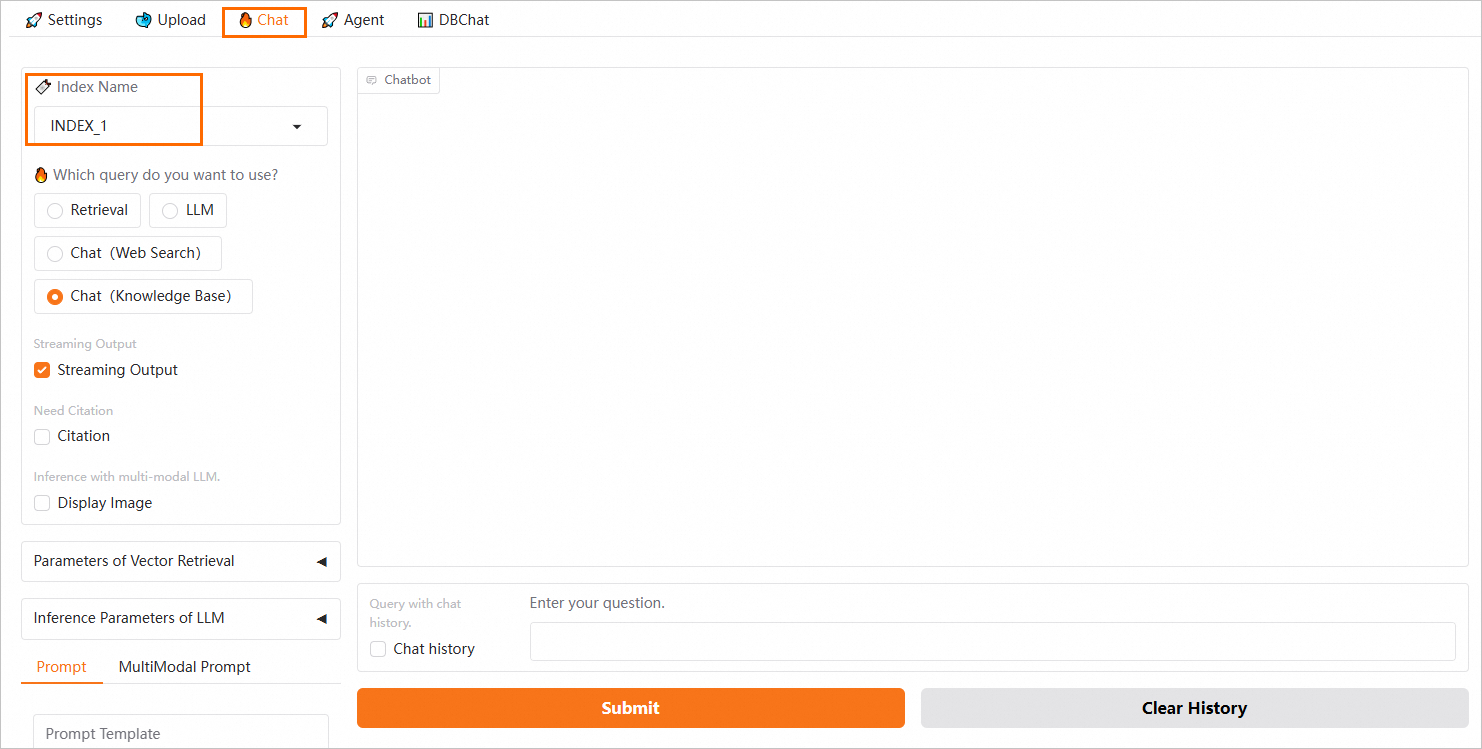
在Chat页签进行对话时,请选择相应的索引名称。系统将使用该索引下的知识库文件进行知识问答,从而实现不同知识库数据的隔离。
在部署大模型RAG对话系统时,仅收取EAS资源的费用。如果在使用过程中,使用了阿里云百炼、向量数据库(如Elasticsearch、Milvus、Hologres、OpenSearch或RDS PostgreSQL)、对象存储OSS、公网NAT网关或网络搜索服务(如Bing、阿里云通用搜索服务)等其他产品,将依据各产品的计费规则在相应产品中单独计费。 停止收费停止EAS服务后,仅能停止EAS资源的收费。若需停止其他产品的收费,请参考对应产品的文档指引,按照说明停止或删除相关实例。 通过API上传的知识库文档可永久使用吗?RAG服务通过API上传的知识库文件并非永久存储,其存储期限取决于所选向量检索库(如对象存储OSS、Elasticsearch、Hologres等)的配置。建议查阅相关文档,了解存储策略以确保数据长期保存。 通过API设置的参数为什么没有生效?目前,PAI-RAG服务仅支持通过API设置接口说明文档中列出的参数,其余参数需通过WebUI界面进行配置,详情请参见。 相关文档EAS针对LLM服务和通用服务场景提供了压测方法,帮助您轻松创建压测任务并进行一键压测,全面了解EAS服务的性能表现。详情请参见服务自动压测。 (责任编辑:) |